记一次软件架构方案的制定
背景是我们的计算软件,依赖于 slurm, k8s 大规模集群软件,导致有些小规模的集群,还要去花费人力成本来安装和维护 slurm 和 k8s 这两款软件,在这样的背景下,领导希望可以不依赖 slurm 和 k8s 也可以进行计算支持。
下面是我画的架构图,etcd 做节点注册和发现,master 做任务管理,worker 做任务执行。数据库维持任务队列,任务状态,任务日志等信息。
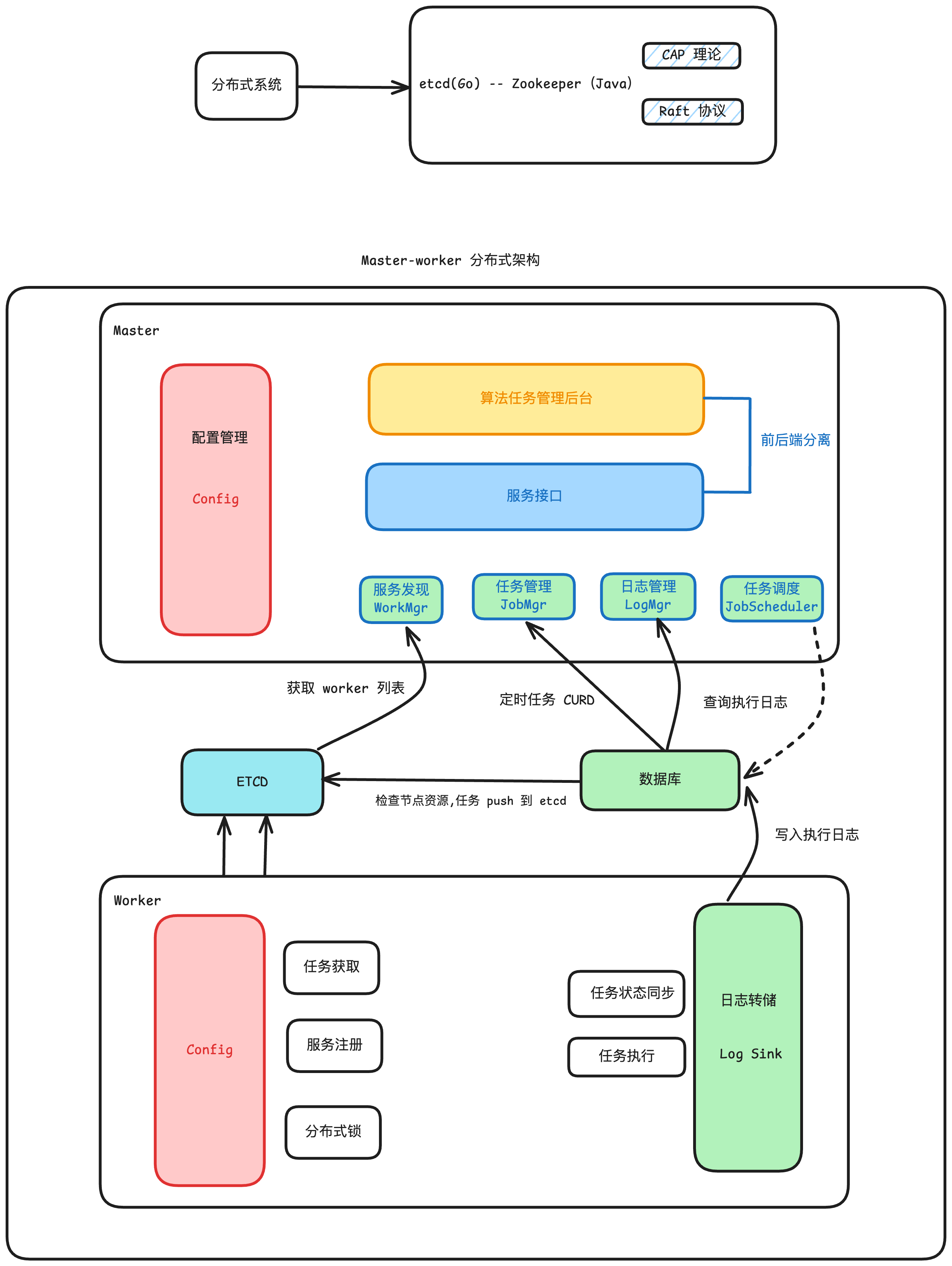
v1 架构图
领导点出的问题是,没有硬件资源分配和节点调度这个环节,也就是说,一个算法可能要占 8个CPU, 2 个 GPU, 8G 内存, 这个节点现在没有这么多资源,怎么调度? 也就是谁来负责 slurm 的任务?
我暂时想到可以在 etcd 里面维持一个节点的硬件资源状态,调度任务的时候,去检测这些节点资源的空余程度,让有空余资源的节点,去抢分布式锁,抢到的会执行任务,并对该节点的硬件资源手动扣减,执行任务结束后, 归还硬件资源。
结尾:领导还是觉得 etcd 太重了,开发时间成本高🤡,决定先做两个版本,第一个是单机版,在数据库实现队列和调度系统,底层不用 slurm, 由数据库控制系统并发。第二个是 slurm 集群版,集群节点由 slurm 来管理,做资源分配和节点调度。
单机版任务调度
下图的图片是每一次算法执行的工作空间。分为数据目录和日志目录,日志目录基本上就是 pid 文件,json 结果文件,标准输出日志和标准错误日志,以及开始和执行脚本。数据目录就是算法的输入文件和输出文件。
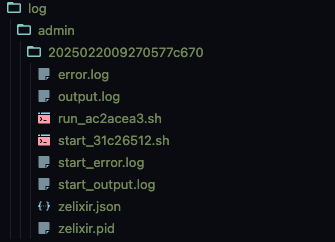
算法工作空间
普通用户任务的状态变化:
PENDING --> RUNNING --> SUCCESS/FAIL
任务队列的任务状态变化:
RUNNABLE --> RUNNING --> ZOMBIE 或者 RUNNABLE --> ZOMBIE